
Case study · Quorum
Quorum is an AI-native product development platform where named agents are the cross-functional team. The methodology is the product; tickets are the output. What follows is the case study of building it — honest about stage, real about the numbers, and visual about the pipeline.
Each step's color = its current state. Green = shipped, purple = designed in prototype, gray = backlog. Updated automatically from sprint-status.yaml.
Screens from the working prototype — these are real renders of the running app at the time of writing.
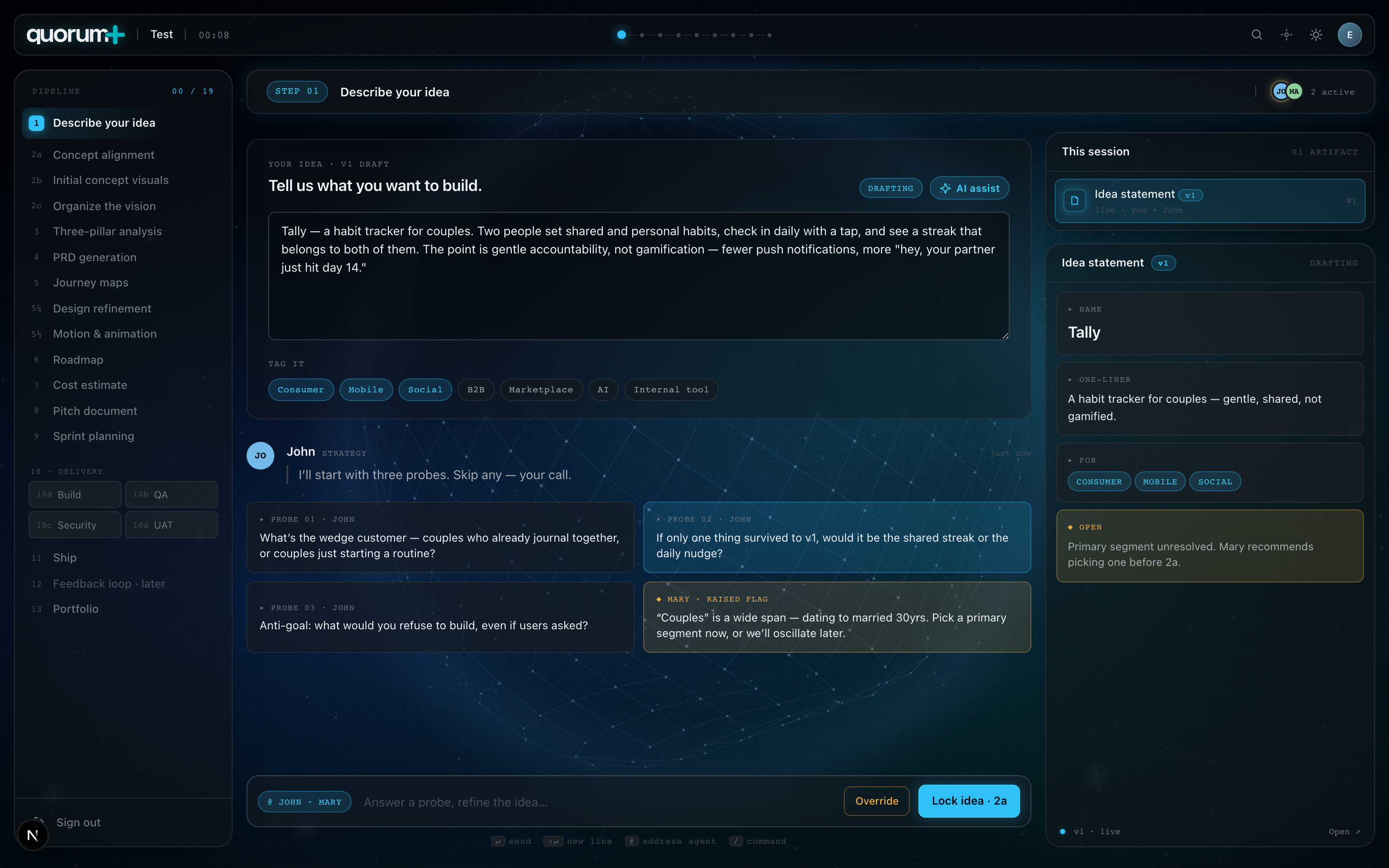
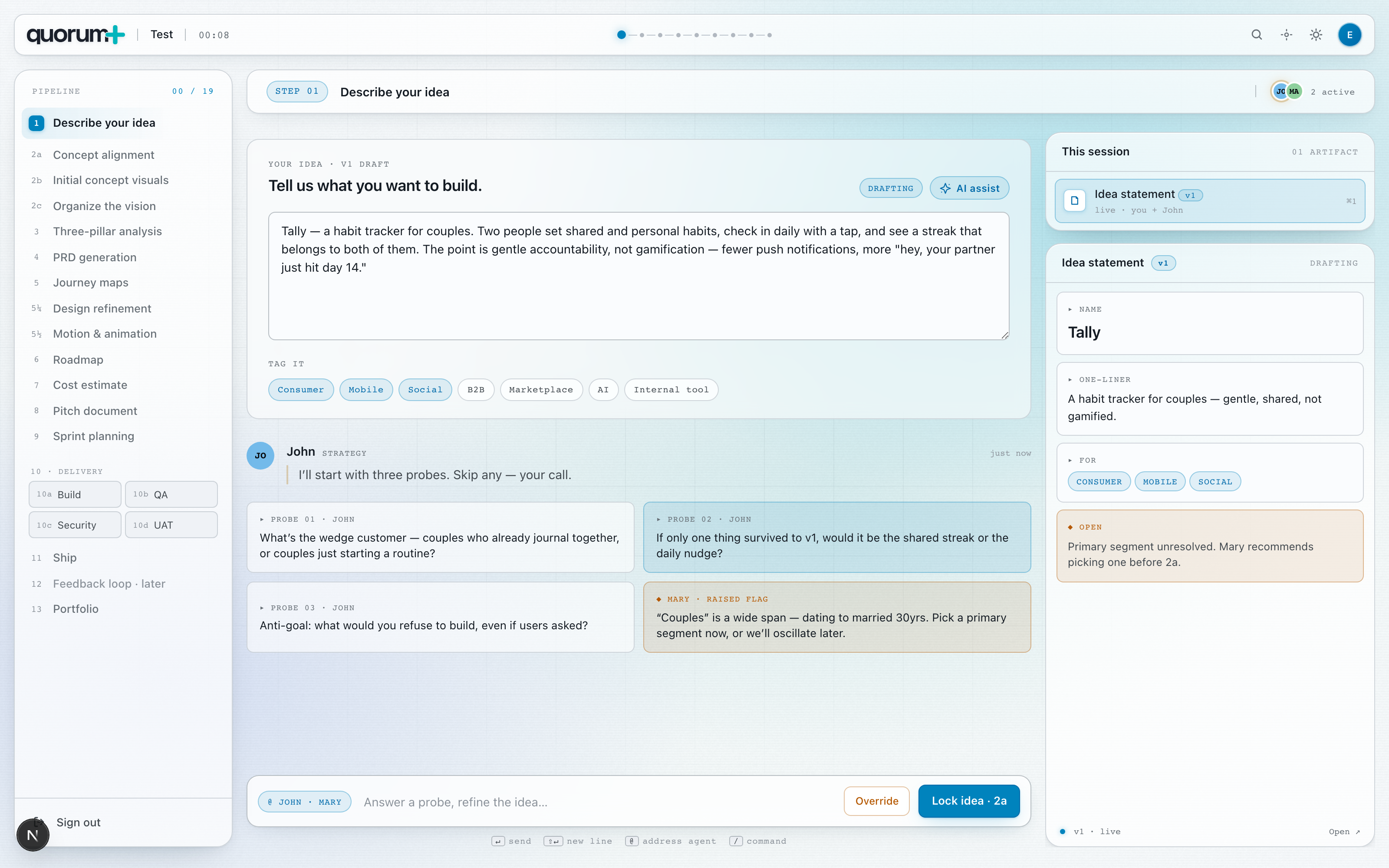
The Step 1 and launchpad screenshots are real renders from the running app. The remaining snapshots get captured automatically as we finish each surface.
| Version | Date | Change |
|---|---|---|
| 0.1 | 2026-04-22 | First draft. Day 8 of the build. Pre-MVP. Honest about stage. |
| 0.2 | 2026-06-06 | Added "The execution phase" section. Documents the human-in-the-loop review system, multi-agent overnight execution, the real accessibility audit, and the design-system consistency push. |
Quorum is an AI-native product development platform where named agents are the cross-functional team. You conduct; they argue, design, build, and ship.
Stage: In progress, about seven weeks in. The planning repo is mature. Epic 1 (auth, workspace creation, billing) is done and retro'd. The application shell and its surfaces (Home, Customize, Account, Settings, Templates, Community, Analytics, onboarding, a command palette) are built and deploying to production behind a waitlist. No open public launch yet.
Most product development tooling is built around tickets. Jira, Linear, Notion. Good at tracking work, wrong shape for generating it.
Actual product thinking still happens in a separate layer: Google Docs, whiteboard sessions, Slack threads. Those artifacts rot. Decisions get lost. The why behind decisions dies first.
AI tools have started plugging into this landscape, but almost always as a sidebar. Assistant inside the ticket tool. The thinking is in the sidebar; the tool is in the foreground. That structural choice subordinates the methodology.
Make the methodology the product. Make tickets the output.
Quorum runs a twelve-step pipeline from first idea to post-ship portfolio. Each step produces artifacts the next step uses. Named agents own their lanes and push back on the user instead of quietly agreeing.
The core mechanism is a three-pillar filter (Desirability, Feasibility, Viability) that runs on a feature list and produces ranked recommendations with evidence. Users can override any recommendation; rationale gets recorded. Over time, that audit trail becomes the Portfolio Document, and this case study.
Twenty-one named agents plus James.
Core Pipeline (10): John (PM), Mary (Analyst), Kinsley (Product Designer), Winston (Architect), Luca (Motion Designer), Paige (Technical Writer), Bob (Scrum Master), Amelia (Developer), Quinn (QA), Barry (Quick Flow Solo Dev).
Creative Specialists (6): Sophia (Master Storyteller), Maya (Design Thinking Maestro), Carson (Brainstorming Specialist), Paul (Master Problem Solver, named after Paul Erdős), Victor (Innovation Strategist), Caravaggio (Visual Communication Expert).
Test Architecture (1): Murat (Master Test Architect).
Dev Team (4): Damien (Backend), Jaymes (Frontend), Cipher (Offensive Security), Quentin (Content Strategist).
Each has a first name, a visual identity, and a distinct voice. Users remember who said what and who disagreed with whom. Accountability lands on characters, not role abstractions.
BMad is James's development methodology, running under Quorum's hood. BMad provides the agent roster, the pipeline steps, the decision-to-artifact flow. Quorum is the product layer on top. Customers never see BMad. They see Quorum.
Users pick a tier before creating an account. Counter to most SaaS, which leads with free trial. The bet: the target user (solo founder, enterprise trio) is serious about shipping and doesn't need a free on-ramp. Friction up front filters for intent.
The biggest structural differentiator: agents push back. When the user gives a vague answer ("users need this"), the agent asks a specific challenge question ("which users, and how did you learn that?"). This is hard to calibrate and easy to get wrong. The line is opinionated without hostile.
Internal BMad skill IDs look like bmad-agent-pm. Product code never sees those. The app reads from a canonical roster at src/features/team/roster.ts with clean IDs like agent-pm. Separation keeps the product layer coherent even as the framework underneath evolves.
WCAG 2.2 AA is the floor. Every story has an accessibility acceptance criterion. Reading level target is grade 9 across all user-facing copy. Content-slice WCAG belongs to Quentin; visual slice belongs to Kinsley; implementation slice belongs to Jaymes. The Voice & Tone Guide enforces it at the copy layer.
Every word users read is drafted without em dashes, filler phrases, or overused buzzwords. The full blacklist lives in the Voice & Tone Guide. This is a positioning move: Quorum does not want to read like AI output, because Quorum is built with AI but is not pretending to be something else.
Stack. Planning uses the BMad method, markdown artifacts, and a Python export pipeline that produces HTML, DOCX, and PDF from single sources. The app uses Next.js 16, TypeScript, Prisma, Playwright, Vitest, and Tailwind. Claude Opus 4.8 (1M context) is the underlying model, with agents vendored into the project via custom skill files.
One repo now. Planning and app started as two repos with separate remotes. On 2026-05-18 they merged into one: the app lives at quorum/app/, brought in via git subtree so its full history is preserved, alongside the planning artifacts. The old quorum-app repo is being archived. The split was the right call early and the merge was the right call once the two halves needed to move together.
Artifacts. PRD, Architecture, UX Design Spec, Voice & Tone Guide, Moments That Matter, Epics & Stories, Builder Portfolio, plus a living change log and a tracked time-log. Eleven epics scoped, sixty-plus stories with acceptance criteria. Epic 1 (auth, workspace creation, billing) is done and retro'd. The Epic 12 application shell shipped, and Epic 2 (the agent collaboration loop) has its next stories specced and in flight.
Shipped surfaces. A real application is now deploying to production, not just mockups: the Launchpad home, Customize ("How your team talks"), Account, Settings, Templates, Community, a shipped-product Analytics view, a warm three-step onboarding, a global command palette, public pricing, a hardened read-only demo, and waitlist capture wired across the hero, the demo, and the in-app nav.
Week count. About seven weeks in as of 2026-06-03, with roughly seventy hours of tracked build time. The planning page totals that figure live from the time-log on every rebuild.
The most interesting thing to happen since the first draft is not a feature. It is how the features get built.
Quorum's own development now runs partly on a fleet of scheduled remote agents. A routine fires overnight, picks up a scoped task (a surface to build out, an accessibility pass, a test-coverage gap, a polish sweep), and opens a draft pull request with a plain-language summary of what it did. The next morning, the work is reviewed and gate-checked locally (typecheck, lint, unit and end-to-end tests) before anything merges, because the remote agents run without database secrets and cannot verify themselves.
Two batches have run so far. The first put up sixteen draft PRs that were verified and merged to main, each merge auto-deploying to production. The second went further: the routines were reconfigured to work as teams, each a lead that spawns specialist sub-agents (an implementer, a domain specialist, an independent reviewer) that iterate before opening one PR per task. That batch put up two dozen more.
This is the thesis turned on itself. Quorum says the cross-functional team can be agents you conduct. Building Quorum this way is the proof: a human sets the intent and holds the merge gate, and a roster of named agents does the cross-functional work in parallel while he sleeps. The audit trail of that work, the PRs and their summaries and this change log, is exactly the kind of record Quorum is designed to produce for its users.
The agent-as-team framing sticks. When James demos flows to reviewers, they remember Kinsley and John as distinct characters. The naming is recognizable. The argument-back behavior is the hook.
Methodology-as-product saves time. Decisions in step 2 flow through to step 7 automatically. No re-explaining.
BMad's rigor compounds. Every artifact traces to an FR and an AC. When something breaks, we chase it back to the decision that created it.
Writing voice discipline early. The Voice & Tone Guide shipped on day 8. Every future surface writes against it. Drift gets caught at the release skim.
Agents that ship while you sleep. Scoping work into routines that open draft PRs overnight changed the pace. Mornings start with a stack of reviewable work instead of a blank editor. The human stays in the one role that matters: deciding what is good enough to merge.
Agent pushback calibration. Too soft, users ignore. Too sharp, users quit. The craft sits in the specific challenge question, not the overall tone.
Portfolio vs. case study boundary. The Portfolio Document (FR47) wanted to cover everything. It kept growing. We split out the Case Study as a distinct artifact to keep both readable.
Schema drift across layers. BMad uses bmad-agent-pm. Product uses agent-pm. Mapping cleanly required a canonical roster file in the app.
Session hygiene. Sibling repos shared context but not commits. The "one repo, one session, one wrap" rule emerged after a few accidents. The 2026-05-18 merge into a single repo retired most of that overhead.
Verifying work you didn't watch happen. The remote agents run without database secrets, so they cannot run the full gate themselves. Their PRs land unverified by design. The discipline is a local verification sweep before any merge: pull each branch, run typecheck, lint, and tests, and rebase the ones that touch the same files. Skipping it would mean shipping plausible-looking work that does not actually compile.
Start the voice guide on day 1. Copy written before the guide drifted and needed re-review. Cheap to avoid.
Plan the repo split before the first commit. Separation was right; the mental overhead of managing two repos emerged only after weeks.
Pre-write the "don't ship as AI tell" rule. Em dashes, filler phrases, synonym-swapping. These are small decisions that feel arbitrary until you ban them collectively. Doing that upfront saves rework.
By June the build had moved from "design the surfaces" to "produce a lot of surfaces, fast, without losing the thread." Three things made that possible without it turning into a slop machine.
The bottleneck was never generating work. It was reviewing it. State-based features (a toast that fires on save, an error screen that shows on a thrown render, a skeleton that flashes during a slow fetch) could not be evaluated by visiting a route, because they only appear on a runtime trigger, and every unauthenticated visitor was redirected to sign-up. The owner's feedback was blunt: this is "not how we designed it AT all," and "how do I even get to this?"
The answer was to build the review surface itself. A public, no-login Feedback & States gallery at /demo/states where each state is driven on demand by a click. A dark, deep-linked review page (visual-review.html) that points straight at each preview. A _review-system/ folder holding the process, the saved verdicts (the owner's actual words, captured per surface), the accessibility report, and the cleanup follow-ups. The loop also rebases each surface right before review so the preview never shows stale UI, and screenshots the real pages via a demo login so review needs no hunting. The principle: do not hand a reviewer raw previews and a list of PR numbers. Hand them a testable scenario and a one-click path to it.
One overnight run turned scattered feedback into nine reviewable draft PRs, a real accessibility audit, and a full backlog rebase. The discipline that kept it safe: exactly one PR shipped to production (the one the owner had already approved); everything else landed as a draft awaiting a verdict. Nothing went live without sign-off. Every rebase used --force-with-lease with recovery SHAs recorded, and the owner's landing team section was verified intact on every single landing PR before anything was touched. Agents are fast; the guardrails are what make fast safe.
Accessibility had been a voice commitment since day one. This phase made it a measured one. The owner asked for an ADA/WCAG agent that would actually test the surfaces and report findings back, not a PR that claimed "a11y fixes" and asked to be trusted. So a real axe-core scan ran against a live server across seven public routes, tagged against WCAG 2.0 through 2.2 AA, and reported zero serious or critical violations, with a full findings table (severity, criterion, file and line, fix) for the incremental hardening that remained. The audit also caught a real defect waiting to happen: two separate accessibility PRs each added their own skip link and main-content id to the same shared shell, which merged together would have produced duplicate ids, an accessibility bug of its own. That reconciliation became its own clean PR. The lesson: an accessibility claim you cannot reproduce with a scanner is a hope, not a result.
Speed across many PRs is where a design system earns its keep or quietly dies. This phase leaned on it hard. Every flat-black modal was re-tokened to the one canonical liquid-glass standard. Every user-facing emoji was replaced with a line icon across twenty-one files. The empty states and inline validation were rebuilt against Material 3 and the app's own real tokens rather than reinvented per surface. A stale grey favicon that looked broken in dark mode was traced to its actual root cause and regenerated. None of this is glamorous. All of it is the difference between a product that feels designed and one that feels assembled.
Build the tool that thinks, not the tool that tracks. The thinking layer is where the value is. Every existing product tool has a tracking layer; very few have a real methodology layer.
Named agents with distinct voices beat role abstractions. The structural differentiation work sits in voice, not architecture. If Kinsley and Damien sound the same, nothing has differentiated.
Dogfood the thesis. If you claim agents can be the team, build the product that way. Quorum is increasingly built by the same kind of agent fleet it sells, with a human on the merge gate. The proof and the product are the same motion.
Write your voice guide before you write your copy. The guide costs one day. Drift costs weeks.
Honesty beats polish. This case study is public before the product shipped. It tells what worked, what didn't, and what day we're on. That's the voice the product earns by shipping honestly.
Inside Quorum, this kind of document is produced at pipeline step 13 (post-ship). The flow:
The Portfolio Document (FR47) is the comprehensive record of the journey. The Case Study is the polished excerpt suitable for external sharing. Both draw from the same source of truth. Both use the project's own visual identity (this file is styled in Quorum's dark-space, cyan-accent aesthetic because that's Quorum's identity; for another project built with Quorum, the case study would use that project's brand).
This case study is the meta case study: Quorum's own case study, written while Quorum is still being built, updated as the build progresses. It doubles as both a test of the format and a public statement of intent.